The requirement was to provide a central point of contact for all customer software in the form of an Internet portal. After ordering a product, the customer can find all documents, tutorials, as well as required software & tools in one place. The application must be easy to use and tailored to the customer’s needs.
Special focus was placed on usability as well as a reliable and future-oriented architecture and technology selection.
In addition, the platform is a central source for documents, products, serial numbers and tools. This data is made available to other internal applications via interfaces.
The sales and administration platform must meet the following requirements:
- Support of different authentication methods, e.g. Single Sign On with PingFederate
- User authorization and role management
- Project management
- Interface to a desktop application for the installation of tools with a custom protocol
- Protected administration area to manage products, resources and users
- Provision of interfaces to other internal applications
- Daily file and database import from other applications
How do microservices help with sales and administration platforms?
Microservice architecture enables fast, frequent and reliable delivery of large, complex applications.
Dividing a large application like these large management platforms into loosely related, specialized services (the microservices) provides the following benefits:
- Faster response to changing business requirements
- Services can be developed in different programming languages
- Services can be developed and delivered independently
- Each service is specialized for one task and can easily be replaced by another
- Frequent delivery of new versions of the software
The microservices were programmed by our team using the Golang programming language. Golang has been developed by Google since 2007 to solve the problems of supporting scalability and effectiveness on cloud infrastructures.
The language offers a simple syntax and a very high performance performance because the code is compiled directly as a binary file. In addition, the low memory requirements (5-15 MB) and the integrated parallelization are also important. The program code is platform-independent and can therefore be used on different operating systems.
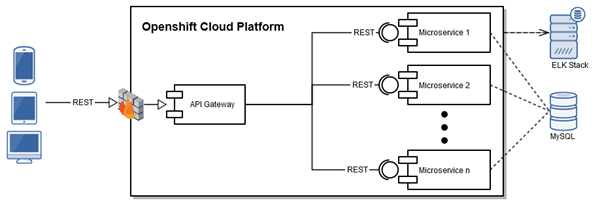
Microservice architecture: Design and communication
The modular structure of our microservices according to the Domain Driven Design allows us to implement additional services in the shortest possible time. So we have one microservices for authentication, one for authorization, one for project management, etc.
The inter-process communication between microservices is done with synchronous HTTP calls. We can thereby ensure a timely response to the client and a consistent state in your database.
If you live with eventual persistency, an event-based distributed transaction might be more suited. Thereby, the microservices would communicate through a message broker with events. The state of this transaction can be logged in the database with a flag in the database table or with a dedicated Events table.
At this point a possible improvement would be the use of events according to the CQRS principle. For example, you could use a message broker with MQTT to ensure that events (messages) are eventually received.
If speed is your concern, the use of HTTP2 and grpc could reduce the latency and the payloads transferred. Grpc uses a binary format, thereby reducing the payload size in comparison to text-encoded messages such as JSON or XML.
As you can see in the figure, the microservices all use the same database for the persistence of data. However, certain tables are assigned to each microservice, which only this microservice is allowed to read and write. A stricter way would have been the allocation of one database per microservice. Due to organizational restrictions and the administrative overhead, we decided against this.
Fail-safe and scalable through Cloud infrastructure
The microservices are stored as executable files in a Docker image. These images are stored in the Enterprise Container Platform “Openshift” provided internally by the company and executed there in containers.
Here, too, we follow the Infrastructure as code approach. This means that the management and provision of containers and the build pipeline is done by machine readable definition files (YAML).
These are stored and versioned like normal program code in our version management system and are therefore easily repeatable and testable. The same is done for the database through migration files in combination with Flyway.
For each new feature branch in Git, a new build and deployment configuration is created from these templates and cleaned up afterwards.
Through the parallel use of redundant replications and dynamic load balancing, we ensure that the productive instances are accessible at all times. Once configured, Openshift takes care of this automatically.
Blue-Green Deployment also eliminates downtime when rolling out new software releases.
Ensure high code quality through continuous integration
The consistent implementation of Continuous Integration, i.e. by running an automated pipeline from the input of a developer’s programming code to the automatic deployment of the software in the Openshift Cloud platform, dramatically accelerates development time.
For each feature branch in Git, Jenkins’ build server automatically generates a new pipeline based on a predefined schema. When executed, Openshift also automates the creation and storage of images and other resources based on predefined templates. Build configurations for the Docker images are created on the fly and removed after a successful image creation.
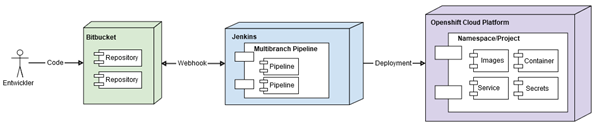
On the one hand, the Jenkins pipelines include the automatic execution of functional tests (e.g. component tests and end-to-end tests) in front-end and back-end. On the other hand, by automatically evaluating syntactic and stylistic rules (Linting), we ensure that only executable and clean code can be pushed. If one of these checks fail, the pull request cannot be merged until the issue is fixed.
Through these merge checks and code reviews (peer reviews) in Bitbucket, we reduce the probability of errors and unimplemented requirements.
Deployments to staging and production are still carried out manually.
Flexibility and reusability in the frontend
In the front-end, too, we attach great importance to modern technologies and reusability.
In the development of the web portal we paid attention to “Responsive Web Design” from the very beginning, i.e. usability independent of screen size and device (PC, smartphone, etc.).
Therefore we use the mobile-first frontend frameworks Bootstrap and Bootstrap Vue in combination with Vue.js. The frontend is running on an nginx server.
With the Vue Design System we extended a library of modular Vue.js components that are used by other applications. This ensures that the company branding is implemented correctly in all projects based on Vue.js.
Finally, we ensure the functional correctness of the graphical user interface in different browsers through end-to-end tests.
Import and validation of data
In order to provide documents, tools and other resources, the online platform has to access some other services and databases.
Automated importers in Openshift are used to import database content and file formats into the database and synchronize them.
We use Openshift Cron jobs running at a predefined schedule. A curl command is executed to retrieve the file to import and passes it on to the respective microservice where its content is processed. For each import, a new pod was created. This allows us to defined assign the resources (CPU, RAM) as needed for each import.
Just make sure that you assign enough memory, otherwise curl might fail with not always comprehensible error messages.
Through validation, we ensure the consistency of the data. Other systems can consume this data via REST interfaces.
To speed up the import process, we are using concurrent Go routines and channels. Goroutines can be thought of as light weight threads. Channels are used for safe communication between these routines.
Monitoring and analysis of microservices during operation
Of course, errors can occur in any technical system. That is why we have warning procedures in place that regularly check all servers, microservices and the website. If a problem is detected, the development team is notified by email.
With the help of the Elastic Stack (Elasticsearch, Logstash, Kibana) we can collect and analyze all processes within the microservices in one place. This allows us to find and fix errors quickly. The use of a unique request identifier for each client request (also spanning several microservices) simplifies the whole thing.
Key figures such as the number of users and registered products are relevant for the business unit. We visualize the figures collected in Kibana with the open source visualization software Grafana.
Conclusion: Advantages and challenges of microservices
Of course, microservices also bring new challenges due to their indirect dependency on each other. For example, it must be ensured that their interfaces remain consistent with one another.
We try to mitigate this issue with a dedicated repository where common code which is used by several microservices is located. This is for example the functionality for connecting to the database or logging.
The central logging and monitoring of the entire microservice platform has paid off in terms of troubleshooting and error correction.
By using microservices and making them available in the Openshift Cloud, we were able to roll out hotfixes and urgent requirements quickly during the project.
The consistent automation of the entire pipeline contributed significantly to this speed and the success of the sales and administration platforms.