
Technische System zeichnen sich heutzutage vermehrt dadurch aus, dass sie mit zahlreichen anderen Systemen kommunizieren, interagieren oder indirekt beeinflusst werden. Das macht den Entwurf dieser Systeme immer komplexer.
Neue Paradigmen für (verteilte) technische Systeme propagieren die Verlagerung von Entscheidungen in die Laufzeit (design-time to run-time). Denken wir nur an den Vormarsch der IoT-Landschaft (z.B. vernetzte Glühbirnen, Smartphones und Kühlschränke).
Diese direkten und indirekten Abhängigkeiten sind beim Entwurf selbst für Experten nicht vollständig absehbar.
Das bedeutet natürlich konsequenterweise, dass wir den Systemen Eigenschaften und Freiheiten zusprechen, damit sich diese innerhalb bestimmter Korridore selbst konfigurieren, selbst optimieren oder selbst adaptieren können – um nur ein paar der sogenannten Selbst-X-Eigenschaften zu nennen.
Die Eigenschaften dieser Systeme wird dabei meist unter dem Begriff Selbstorganisation zusammengefasst.
Architektur für verteilte, selbstorganisierende Systeme
Eines dieser Entwurfsparadimen stammt aus dem Bereich des Organic Computing. Es postuliert die Aufteilung der Systeme in Observer und Controller-Einheiten.
Der Observer dient als Schnittstelle zum Produktivsystem. Er übernimmt Aufgaben wie Logging, Aufbereitung der Sensordaten oder Vorhersagen des Systemverhaltens. Hauptsächlich stellt er jedoch eine Beschreibung des aktuellen Systemzustandes zusammen, die er dem Controller übergibt.
Der Controller berechnet auf Grund dieser Zustandsbeschreibung, seinem Wissen und den vom Nutzer bestimmten Systemzielen inwiefern das Produktivsystem angepasst werden muss. Schlussendlich führt er diese Änderung über Schnittstellen auf dem Produktivsystem aus.
Der Controller kann auf Basis einfacher Heuristiken entscheiden, wird aber meist mit Hilfe eines maschinellen Lernalgorithmus umgesetzt. Dieser aggregiert zur Laufzeit neues Wissen und verbessert sich so kontinuierlich.
Selbstorganisierte technische Systeme
Das Einbringen von Adaptivität und Selbstorganisation in technische System hat zum Ziel robuste und flexible Lösungen zu schaffen.
Adaptivität bedeutet, dass das System die Möglichkeit hat (z.B. durch Redundanz von Ressourcen) sich zur Laufzeit selbstständig auf neue Ziele einzustellen oder die Erfüllung der durch den Nutzer definierten Ziele zu gewährleisten.
Selbstorganisation bedeutet, dass die Ziele durch das Zusammenspiel der Komponenten in einer autonomen Weise durch das System erreicht werden.
Resilienz technischer Systeme
In diesem Kontext möchte ich den Begriff Resilienz einführen. Resilienz wird oft als Fähigkeit oder Eigenschaft eines Systems beschrieben. Dabei ist die Reaktion gemeint, dass ein System bei negativen Ereignissen, Ausfällen oder Einflüssen nicht vollständig ausfällt, sondern über einen möglichst kurzen Zeitraum wieder selbstständig – ohne menschlichen Eingriff – in seinen optimalen Zustand zurückfindet.
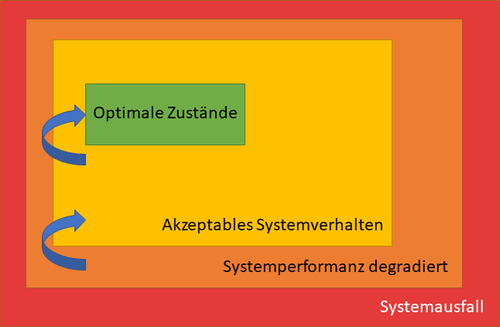
Ein System kann sich somit in einem von verschiedenen Zustandsbereichen befinden, die die Qualität des erbrachten Dienstes beschreiben (denken wir z.B. an Service Level Agreements und Quality of Service).
Im Zielzustandsbereich (target space) wird die Aufgabe für die das System entworfen ist, optimal erfüllt (Nehmen wir ein Auto, bei dem alles wunderbar funktioniert).
Danach befindet sich der akzeptable Zustand (Acceptance space), in dem das System noch gut funktioniert (unser Auto beschleunigt nicht so gut wie sonst).
Außerhalb dieses Zustandes funktioniert das System zwar noch, die Erbringung seiner Aufgaben ist jedoch eingeschränkt (Der 5. Gang ist ausgefallen). Wir erwarten, dass sich das System mit Hilfe seines selbstorganisierten Kontrollmechanismus aus diesem Zustand (survival space) in einen der ersten beiden zurückbewegen kann.
Schlussendlich gibt es noch den Zustandsbereich, in dem unser System ausgefallen ist (Dead space).
Wir stehen am Standstreifen und warten auf den Abschleppdienst. Aus diesem Bereich kann sich das System nicht mehr selbst erholen. Je unwahrscheinlicher es ist, dass ein System den Ziel- oder Akzeptanzbereich verlässt, desto robuster ist es.
Resilienz durch Proaktivität
Kommen wir nach diesem kurzen Exkurs wieder auf den Begriff Resilienz zurück. Oft wird dieser als reaktive Fähigkeit eines Systems beschrieben. Das System kann sich und seine Umgebung wahrnehmen und reagiert auf Änderungen. Diese Eigenschaft wird auch als Flexibilität bezeichnet.
Diese Änderungen geschehen in Hinblick auf die Optimierung bzgl. einer Zielfunktion. Andererseits beinhält Resilienz jedoch auch einen proaktiven Aspekt. Das bedeutet, dass wir Vorhersagen über zukünftige Ereignisse und Performanzmetriken erheben und Gegenmaßnahmen ergreifen bevor diese eintreten.
So könnte man z.B. die gemessenen Sensorwerte eines Bauteils als Zeitreihe betrachten und mit Hilfe von Vorhersagenmethoden zukünftige Werte und Trends abschätzen. Ein möglicher Ausfall unseres Bauteils wäre somit bemerkbar bevor es tatsächlich ausfällt und möglicherweise weiteren Schaden verursacht.
Schlüsselfaktoren für die Erhöhung der Resilienz verteilter technischer Systeme sind somit u.a. Proaktivität, Flexibilität und Robustheit.
Von reaktiver Kontrolle zu proaktivem Verhalten
Um ein reaktives in ein proaktives System zu überführen, müssen folgende Schritte durchgeführt werden:
- Identifizierung von kritischen Aspekten im System, die die Stabilität oder Performanz beeinträchtigen können.
- Implementierung einer Komponente zur Vorhersage zukünftigen Systemverhaltens, Sensorwerte und Zeitreihen.
- Anbindung der Komponente an Module des Systems, die Vorhersagen benötigen.
- Erstellung der Vorhersagen.
- Adaptation des Verhaltens durch Einbeziehung der Vorhersagen.
Typischerweise hat die Vorhersagekomponente ein einfaches Interface, so dass diese unkompliziert eingebunden werden kann:
public class ForecastComponent {
public void addSensorValue(Value value);
public double getForecast(int timestep);
public double getForecastError();
}
Wir wollen also Sensorwerte (evtl. samt Zeitstempel) abspeichern, Vorhersagen für einen bestimmten Zeitschritt oder Zeitpunkt in der Zukunft berechnen lassen oder uns einen Wert für die Genauigkeit der Vorhersagen ausgeben lassen.
Der letzte Punkt ist wichtig, um ein Gefühl dafür zu bekommen, inwiefern man den Vorhersagen vertrauen kann und diese in Algorithmen einbeziehen sollte.
Je besser die gewählte Metrik (z.B. MASE oder SMAPE) die Vorhersage einschätzt, desto höher wählt der Algorithmus die Gewichtung der Vorhersage.
Andersrum verlasse ich mich lieber auf die Sensorwerte als Fallback-Mechanismus wenn die Vorhersagen momentan schlechter ausfallen.