
I am pretty sure you heard of neural networks. They are applied to tasks ranging from creation of images to Automatic Colorization of Black and White Images. However, there are plenty other machine learning algorithms and architectural approaches, to make computer systems smarter and more life-like. Organic Computing follows the idea of transferring principles observed in nature to technical systems. In the following, I would like to introduce the basic concepts of this fascinating idea.
What is Organic Computing?
The technical systems that sourround us are getting smarter and more flexible.
Just think of the stereo system that starts to play your favorite music when you enter your living room. However, this technical development bears new challenges.
We have to design these intelligent systems in a way that they are robust, safe, and flexible while also being controllable and trustworthy.
Organic Computing proposes new approaches to design technical systems that realise these properties.
We call them organic systems.
These system have the ability to observe their environment and the capabilities to adapt to changing environmental conditions.
Self-*-Properties
To deal with unexpected or undesired conditions, these systems exhibit several of the following self-* properties:
- self-organising
- self-adapting
- self-configuring
- self-healing
- self-protecting
- self-explaining
- there are even more
As far as i know, IBM were the first to propose a concept for systems implementing these properties.
Consequently, organic computing systems are said to exhibit life-like behaviour. In my oppinion, the biological equilavent is somehow far-fetched. It’s the same with neural networks and the brain. Their principles have some similarities with the brain, however they are very simplified.
Life-like behaviour with Organic Computing
But how do we build systems that adapt without human intervention and improve their performance over time through learning of the best reaction to certain situations? To achieve this goal, Organic Computing builds upon other research directions:
- Machine learning
- Optimisation
- Multi agent systems
- Human machine interaction
Machine learning
In order to learn, we need an algorithm that has some kind of knowledge which it can use to select a suitable action for a certain task or situation.
Furthermore, the knowledge has to be reinforced according to the received reward after executing a certain action (this is called reinforcement learning).
Machine learning (ML) is a vivid research area with numerous algorithms. It ranges from decision trees to sophisticated (and more complicated) algorithms, such as support vector machines, artificial neural networks, or learning classifier systems.
Mostly, these ML systems have the characteristic that their interal model is not human-readable.
However, in a real-world system you would prefer a technique that is interpretable, e.g. to analyse its behaviour at runtime by a system engineer .
Optimisation
In order to improve, the organic computing systems needs to know its task and a measure to evaluate the attainment of this task.
The task is usually defined by humans. In case of a production cell, the task would define how a certain workpiece has to be assembled.
The organic computing system optimises the number of workpieces finished in a certain time period.
To achieve this optimisation, the system has to have some degrees of freedom, e.g. it could reallocate the subtask a certain robot has to carry out.
Multi agent systems
Usually, organic systems are not isolated but work together with other intelligent systems.
Therefore, they have to interact by exchanging resources and information.
Each of these systems resembles an agent. Each agent autonomously follows its own goals, also respecting the goals of other agents. Such a connected environment is called multi agent system.
Most of all, the exchange of knowledge and the interaction enables these agents to achieve a higher goal which could not be achieved by any of its individual agents (this phenomenon is called emergence)
Human machine interaction
Mostly, technical systems and multi agent systems are not cut off from the outside world, but interact with humans. Consequently, an important aspect is how we design interfaces for humans to interact with these intelligent systems.
Approaches range from standard graphical user interfaces to augmented reality concepts.
Building Organic Computing systems
At last, i would like to give you a glimpse of how we would actually create an organic computing system.
Usually, we already have a productive system in place. On top of this, we place our observer/controller pair.
It extends the underlying productive system and transforms the standard system into an organic computing system. Furthermore, it adds the ability to monitor and control the system.
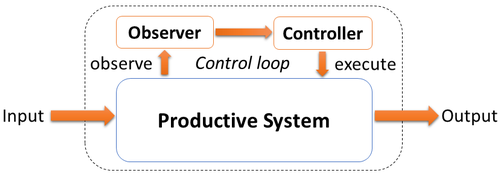
The observer observes the underlying productive systems via sensors. It monitors its current state and analysis the current and previous conditions.
Furthermore, it can derive forecasts and it creates a situation description.
Based on this situation description, the controller selects actions that will be executed on the productive system.
The controller is configured with the system’s task. Its goal is to enforce actions on the system so that it works optimally.
Usually, the controller has some kind of knowledge, where it stores situation-to-action pairs.
The action selection process is often executed with the help of a machine learning technique.